
2021.09.05 / 很多人來瀏覽這篇,這是 9 年前的文章,在採納許多人的建議後,國發會已經讓許多政府網站陸續更新,同時,我也離開「網站企劃」這個工作好一陣子。常常都是離開後再回頭看,會有更多感想,而且也比較不負面。如果你看到這篇或在搜尋引擎中看到這篇,請你也看看我在 9 年後寫的這篇文章:台灣政府網站的改變 (2021年更新自己對政府網站的認知)。
當我實際與國外的團隊一起工作,從他們的需求來看台灣政府網站時,覺得台灣政府網站並沒有太差,進步的速度看起來有點慢,除了從業人員的求好心切外,也要考量改版後民眾可能找不到資訊的挫折感。就看新的文章吧!人不能一直活在過去。台灣政府網站的改變 (2021年更新自己對政府網站的認知)。
這幾個月來,因為工作緣故,會去瀏覽公部門的網站,陸續的把這些資訊拋在G+裡,偶爾會引起一些迴響,我也發現G+裡使用族群的不同,不過這是題外話。
每個公部門的網站都會有一些公示資料,而這些公示資料是哪些人會去看?不得而知。但我最常聽到的是一般民眾會說:- 不知道要到哪找資料?
- 到了網站後,不知道要找哪些資料?
公部門網站都是IE Only,我不用__(請自行填入)。下圖是臺灣大學的網站典藏庫(http://webarchive.lib.ntu.edu.tw/),在政府機構項目下,收錄了1,579筆資訊,問問自己,平常看過哪些呢?

我問自己在天天搜尋政府新聞的狀況下看了哪些網站?似乎也不到裡面的二分之一,。當然還有很多是沒有收錄進典藏庫的活動計畫網站,就更不用說了。
其實不太清楚為什麼臺灣人民不怎麼喜歡瀏覽公部門的網站,在以往可能因為網路技術不是那麼發達,而部份公部門會過度使用一些當時較流行的技術做視覺展現,所以大家會拒絕去看那樣的網站。
至於以前的我為什麼不看?因為我覺得,自己用不上那些資訊,直到有天我發現,我必須要取得稅法資訊、了解勞基法資訊時,有天我驚覺接案以來都是公部門網站後,也開始看這些網站的資訊,然後,我也開始用SNS來幫公部門操作網站行銷。
我覺得,每個人都應該去了解我們的公部門網站能提供什麼樣的資訊給我們,就不會一直被有心的政客及媒體刻意隱瞞訊息,也不會有天要用到資訊時才發現:我怎麼現在才知道?不可否認,台灣的公部門網站資訊公開設計上,的確是很吊詭,有很多資訊對民眾來說不是那麼明顯的就能自網站上找到。
經過這次2012總統大選,大家開始好奇:我們繳的稅到哪去了呢?
我們可以先到行政院主計處的網站去看每年的預算。 行政院主計處網站路徑為:政府預算→中央政府預算及附屬單位預算→中央政府預算簡介及總覽頁面中看到每年度的預算,而主計處的網站中可以取得相當多政府各部會預決算的編列和執行的狀況,格式多為Excel或是PDF:

另外就是中華民國統計資訊網,可以了解整體經濟環境的資訊。許多網站所公布的統計資訊都能在其中看到,例如之前所提到的主計處、財政部、中央銀行、交通部、經濟部等主要部會網站的統計資訊都有。現代人的教育程度頗高,裡面的統計資訊應該都能看懂,儘量讀媒體報導的財經資訊的同時,搭配著原始政府統計資料來源來閱讀,可以減少被文字遊戲愚弄的狀況。儘管媒體都會儘量保持其公正立場,但閱讀者也要有時時驗證的態度:

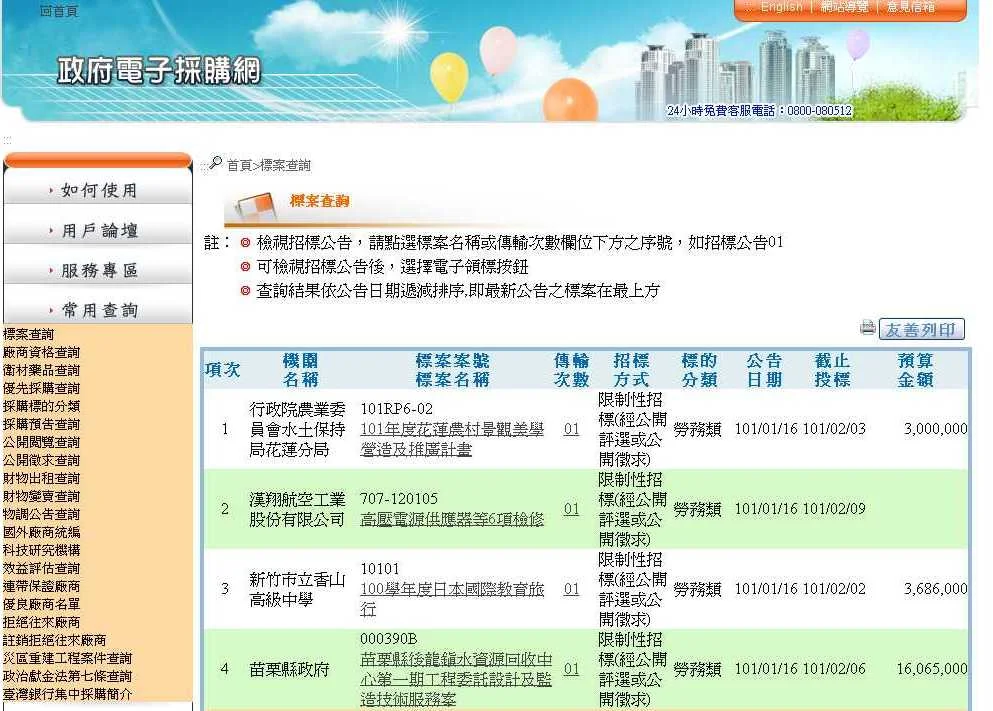
像是政府電子採購網也可以查詢每個政府公開招標的資訊,雖然說一定要領標才能見到招標案件的內容,但也可以大概從公開的資訊了解到每個案子,政府預算花多少錢在上面?你也可以看到哪些案件是由哪些廠商所得標?條件是什麼?
簡單而言,當瀏覽者到了公部門的網站,依照研考會的規範,部會院層級的網站都會有一個名為「公開資訊」或「主動公開之政府資訊」的項目,不是那麼的好找,但找到了,再有點耐心去下載資料,通常都會取得大量的資訊,有些需要自己過濾,有些則是連來連去的,或是因為格式的問題而造成瀏覽上的不方便。目前較常見的格式為PDF和Microsoft Office格式的檔案,也許不方便,但已經是公部門進行公開資料的第一步。
同時,也為了因應網路技術的進步和溝通管道的多樣化,有些部會也提供了一些SNS或是Facebook等社交網站的管道,除了知名的總統府外,其他例如財政部、農委會都有提供這樣的管道與民互動,而不像以前只有email或留言板的方式。
除了各部會的網站外,也有許多政府計畫同樣也有Facebook或是Plurk、Twitter在做溝通,例如臺北市SBIR、去年舉辦的建國百年經建特展等,也有提供Facebook的粉絲頁面在做互動及宣傳。
其實這幾年,主要的公部門網站多可以用Chrome、Firefox(Safari、Opera應該也可以吧?)等非微軟家族的瀏覽器瀏覽,門檻較以往低了許多。
在國際間,開放資料已是一個必然的趨勢,目前可以看到英國有data.gov.uk,法國有http://www.data.gouv.fr/,美國也成立了data.gov。在台灣,目前也可看到台北市政府公開資料平台(http://data.taipei.gov.tw/)。
1月18日,這個星期三,有一場「我國政府資料加值(Open Data)推動策略會議」將在台大醫院國際會議中心舉辦,很期待裡面的來賓及內容。可惜的是,報名人數已滿,已經無法報名了。很期待臺灣的公部門能慢慢的把這些資料用一種公開且易取得的方式讓全民都能參與其中,而不是把資料藏到人民都看不到。
我們是一個民主開放的國家,不是嗎?在這個轉換期中,我們先開始學習瀏覽及理性的解析公部門網站吧!
謝謝您整理這些資訊。最近的新聞也讓我想到,如果十二年國教的課程的教材,還有上課內容皆可製作成開放課程,這樣可改變使用教科書的方式,減少城鄉差距,同時可以讓回流教育的民眾在學習上更有彈性哩。
回覆刪除我的留言回覆系統可能壞了XD
回覆刪除在國外,有一些行之有年的開放課程可以參考:
美國麻省理工學院就有所謂的Free Online Course(http://ocw.mit.edu/index.htm),台灣也有中文化網頁:http://www.myoops.org/twocw/mit/index.htm
另外,耶魯大學也有:http://oyc.yale.edu/
另外也有 400 Free Online Courses from Top Universities 這篇文章可以參考
http://www.openculture.com/freeonlinecourses